Introduction
Cet article offre un aperçu des concepts fondamentaux du Machine Learning et explique son utilisation croissante dans le secteur de la cybersécurité, ses principaux avantages et cas d’usage, les idées reçues courantes et l’approche adoptée par CrowdStrike en la matière.
Qu’est-ce que le Machine Learning ?
Le Machine Learning (ML) est un sous-ensemble de l’intelligence artificielle (IA). Il désigne le processus d’entraînement d’algorithmes pour qu’ils identifient des schémas au sein des données existantes afin de prédire les réponses pour de nouvelles données.
Bien que les termes IA et ML soient souvent utilisés de manière interchangeable, il existe des différences majeures entre les deux concepts. L’IA désigne la technologie qui entraîne les machines à imiter ou à simuler les processus d’intelligence humaine en environnement réel, tandis que le ML désigne les systèmes informatiques en résultant (« modèles ») qui tirent des enseignements des données pour effectuer des prédictions.
Concrètement, l’apprentissage est le processus par lequel les modèles appliquent des fonctions mathématiques pour transformer des données sous-jacentes en vue d’effectuer des prédictions précises. Alors que les ordinateurs peuvent être programmés pour réaliser des tâches simples et prévisibles en suivant des instructions explicitement programmées ou chaînées, les modèles de ML développent une approche généralisée de la résolution des problèmes.
Trois types de Machine Learning
Cet article s’intéresse à trois types courants de Machine Learning :
1. Apprentissage supervisé
Avec l’apprentissage supervisé, un modèle est entraîné à partir d’entrées étiquetées et de résultats souhaités, dans l’objectif de lui apprendre à réaliser une tâche lorsqu’il rencontre des données nouvelles ou inconnues. En cybersécurité, une utilisation courante de l’apprentissage supervisé consiste à entraîner des modèles à partir d’échantillons inoffensifs et malveillants pour leur apprendre à prédire si de nouveaux échantillons sont malveillants.
2. Apprentissage non supervisé
Avec l’apprentissage non supervisé, un modèle est entraîné à partir de données non étiquetées et doit identifier une structure, des relations et des schémas au sein de ces données, comme des clusters ou des groupes. En cybersécurité, il permet notamment d’identifier les nouveaux modes opératoires des attaques ou les nouveaux comportements des cyberadversaires (p. ex., détection des anomalies) au sein d’importants volumes de données.
3. Apprentissage par renforcement
Avec l’apprentissage par renforcement, un modèle n’est pas entraîné à partir d’entrées ou de sorties étiquetées, mais apprend de ses expériences, de façon à optimiser une récompense cumulative. Ce type de Machine Learning est fortement inspiré de l’apprentissage humain et s’avère particulièrement utile pour identifier des méthodes créatives et innovantes de résolution des problèmes. Les cas d’usage de l’apprentissage par renforcement en cybersécurité incluent les systèmes cyberphysiques, la détection autonome des intrusions et la lutte contre les attaques par déni de service distribué (DDoS).
Avantages du Machine Learning en cybersécurité
L’utilisation du Machine Learning pour résoudre les problèmes de cybersécurité présente de nombreux avantages, dont les suivants :
- Synthétisation rapide d’importants volumes de données : l’un des principaux défis pour les analystes consiste à synthétiser la cyberveille générée sur toute leur surface d’attaque, qui est généralement créée bien trop vite pour que leurs équipes puissent la traiter manuellement. Le Machine Learning permet d’analyser rapidement d’importants volumes d’informations de cyberveille historiques et dynamiques, ce qui permet aux équipes d’opérationnaliser les données provenant de diverses sources en temps quasi réel.
- Collecte de cyberveille de pointe à grande échelle : des cycles d’entraînement réguliers permettent aux modèles de tirer constamment des enseignements de leur population d’échantillons en perpétuelle évolution, ce qui inclut les détections étiquetées par les analystes et les alertes examinées par ces derniers. Vous éviterez ainsi les faux positifs récurrents et permettrez aux modèles d’apprendre et d’appliquer une vérité terrain définie par des experts.
- Automatisation des tâches manuelles répétitives : l’application du Machine Learning à des tâches spécifiques peut soulager les équipes de sécurité des processus routiniers et répétitifs en agissant comme un multiplicateur de force qui leur permet d’adapter leur réponse aux alertes entrantes et de réallouer du temps et des ressources à des projets stratégiques complexes.
- Amélioration de l’efficacité des analystes : le Machine Learning peut compléter les informations des analystes par une cyberveille à jour en temps réel, ce qui permet à ceux chargés du Threat Hunting et des opérations de sécurité de prioriser efficacement les ressources pour corriger les vulnérabilités critiques de leur entreprise et enquêter sur les alertes urgentes générées par le ML.
Cas d’usage du Machine Learning en cybersécurité
Le Machine Learning répond à un large éventail de cas d’usage en cybersécurité. Ces cas d’usage peuvent être divisés en deux catégories principales :
- Détection des menaces et intervention automatisées
- Opérations dirigées par les analystes et assistées par le Machine Learning
Détection des menaces et intervention autonomes
Dans la première catégorie, le Machine Learning permet aux entreprises d’automatiser les tâches manuelles, en particulier dans les processus où il est essentiel de préserver des niveaux élevés de précision, et d’agir à la vitesse d’une machine (p. ex., détection des menaces et intervention automatiques, ou classification des nouveaux modes opératoires des cyberadversaires).
Dans ces situations, le Machine Learning optimise les méthodes de détection des menaces basées sur les signatures grâce à une approche généralisée qui apprend à faire la différence entre les échantillons inoffensifs et malveillants, et qui permet de détecter rapidement les nouvelles menaces en circulation.
Amélioration de l’efficacité des analystes grâce au Machine Learning
Les modèles de Machine Learning peuvent également faciliter les investigations dirigées par les analystes en indiquant aux équipes d’enquêter sur certaines détections ou en identifiant les vulnérabilités pour lesquelles des correctifs doivent être appliqués en priorité. L’examen réalisé par les analystes peut s’avérer particulièrement précieux lorsqu’il n’y a pas assez de données pour que les modèles puissent prédire des résultats avec un degré élevé de confiance ou pour enquêter sur des comportements en apparence inoffensifs qui peuvent tromper les classificateurs de logiciels malveillants.
Autres cas d’usage du Machine Learning en cybersécurité
Voici une liste d’exemples courants (non exhaustive) de cas d’usage du Machine Learning en cybersécurité.
| Cas d'usage | Description |
|---|---|
| Gestion des vulnérabilités | Définit la priorité des vulnérabilités en fonction de leur niveau de criticité pour les équipes informatiques et de sécurité |
| Analyse statique des fichiers | Prévient les menaces en prédisant la malveillance des fichiers à partir de leurs caractéristiques |
| Analyse comportementale | Analyse le comportement des cyberadversaires lors de l'exécution pour modéliser et prédire les schémas d'attaque à tous les stades de la cyberchaîne d'attaque |
| Analyse hybride statique et comportementale | Combine analyse statique des fichiers et analyse comportementale pour détecter les menaces avancées |
| Détection des anomalies | Identifie les anomalies au sein des données pour définir des scores de risque et orienter les investigations sur les menaces |
| Analyse d'investigation | Mène un contre-espionnage pour analyser la progression des attaques et identifier les vulnérabilités système |
| Analyse antimalware en environnement sandbox | Analyse les échantillons de code dans des environnements sûrs et isolés pour identifier et classifier les comportements malveillants et les attribuer à des cyberadversaires connus |
Évaluation de l’efficacité des modèles machine
Efficacité des modèles pour les classificateurs de logiciels malveillants :
La classification des logiciels malveillants fait partie des cas d’usage les plus courants du ML en cybersécurité. Les classificateurs de logiciels malveillants fournissent une prédiction avec un score déterminant si un échantillon donné est malveillant. Ce score correspond au degré de confiance associé à la classification. L’une des méthodes d’évaluation des performances de ces modèles consiste à représenter les prédictions sur deux axes : la précision (si un résultat a été correctement classifié ; « vrai » ou « faux ») et le résultat (la classe qu’un modèle attribue à un échantillon ; « positif » ou « négatif »).
Dans ce contexte, les termes « positif » et « négatif » ne signifient pas qu’un échantillon est « inoffensif » ou « malveillant », respectivement. Si un classificateur de logiciels malveillants fait une détection « positive », cela indique que le modèle prédit qu’un échantillon donné est malveillant, d’après l’observation de caractéristiques qu’il a appris à associer à des échantillons malveillants connus.
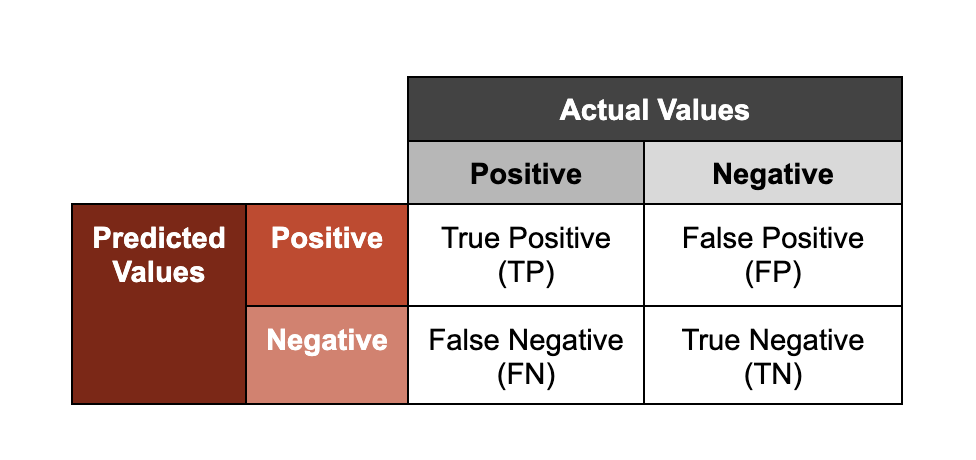
Pour illustrer à quoi correspondent ces groupes, prenons l’exemple des modèles entraînés à analyser des fichiers malveillants.
- Vrai positif : le modèle a correctement prédit qu’un fichier était malveillant.
- Vrai négatif : le modèle a correctement prédit qu’un fichier n’était pas malveillant.
- Faux positif : le modèle a prédit qu’un fichier était malveillant, alors qu’il ne l’était pas.
- Faux négatif : le modèle a prédit qu’un fichier n’était pas malveillant, alors qu’il l’était.
Trouver le juste équilibre entre vrais et faux positifs
Bien que les vrais positifs soient essentiels pour la détection des menaces et l’intervention, les faux positifs constituent également une mesure importante des performances des modèles. Les faux positifs représentent un manque à gagner en raison du temps et des ressources que les équipes de sécurité consacrent à l’investigation de chaque détection, et peuvent s’avérer particulièrement coûteux s’ils déclenchent des processus de correction automatiques qui bloquent ou interrompent des applications indispensables aux activités d’une entreprise.
Lors de l’étalonnage de l’agressivité ou de la sensibilité des modèles, les scientifiques des données doivent trouver le juste équilibre entre le taux de vrais positifs et le taux de faux positifs : en effet, abaisser le seuil pour les vrais positifs (c’est-à-dire les exigences qui doivent être satisfaites pour qu’un modèle classifie un échantillon comme « positif ») risque d’abaisser également le seuil pour les faux positifs (ce qui pourrait nuire à la productivité des analystes et aggraver la lassitude face aux alertes répétées). Nous appelons cet équilibre fragile l’efficacité de détection.
L’objectif ultime de la création de modèles hautes performances de Machine Learning est d’optimiser l’efficacité de détection : optimiser la détection des vrais positifs tout en réduisant les faux positifs. Pour mieux saisir la complexité de cet équilibre, rappelez-vous qu’il n’est pas rare que les classificateurs de logiciels malveillants affichent des taux de vrais positifs avoisinant les 99 %, contre des taux de faux positifs bien inférieurs à 1 %.
Défis et contraintes liés au Machine Learning
Si les modèles de Machine Learning peuvent être des outils puissants, tous présentent des limites :
Données de haute qualité en quantité suffisante : l’entraînement de modèles extrêmement fiables requiert souvent un accès à de vastes référentiels de données pour entraîner et tester les modèles de Machine Learning. Un sous-ensemble des données d’entraînement est généralement mis de côté pour tester les performances des modèles. Ces données doivent avoir peu de caractéristiques en commun avec les données d’entraînement. Elles doivent par exemple couvrir une autre période de collecte ou émaner d’une autre source de données. En l’absence de données de haute qualité en quantité suffisante, il est possible que le Machine Learning ne puisse pas contribuer à la résolution d’une catégorie de problèmes donnée.
Équilibre entre vrais et faux positifs : comme mentionné précédemment, la sensibilité de chaque modèle doit être étalonnée pour équilibrer le seuil de détection des vrais et des faux positifs afin d’optimiser l’efficacité de détection.
Explicabilité : l’explicabilité est la capacité à expliquer comment et pourquoi un modèle fonctionne comme il le fait. Les équipes d’analyse scientifique des données peuvent ainsi déterminer les caractéristiques d’un échantillon qui influencent les performances du modèle et leurs pondérations relatives. L’explicabilité est primordiale pour renforcer la responsabilité, établir une relation de confiance, assurer la conformité aux règles de protection des données et, en fin de compte, permettre l’amélioration continue des performances du Machine Learning.
Répétabilité : également connu sous le nom de reproductibilité, ce concept désigne la capacité des expériences de Machine Learning à être reproduites de façon cohérente. La répétabilité renforce la transparence autour de l’utilisation du Machine Learning, des types de modèles employés, des données servant à leur entraînement, ainsi que des versions et environnements logiciels dans lesquels ils sont exécutés. La répétabilité réduit l’ambiguïté et les erreurs potentielles depuis les tests jusqu’au déploiement, et tout au long des futurs cycles de mise à jour.
Optimisation pour l’environnement cible : chaque modèle doit être optimisé pour son environnement de production cible. La disponibilité des ressources informatiques, la mémoire et la connectivité de chaque environnement varient. Par conséquent, chaque modèle doit être conçu pour s’exécuter dans son environnement de déploiement, sans entraver ni interrompre les opérations de l’hôte cible.
Protection renforcée contre les attaques cybercriminelles : les modèles de Machine Learning ont leur propre surface d’attaque, qui peut être vulnérable aux attaques cybercriminelles, au cours desquelles les cyberadversaires peuvent tenter d’exploiter ou de modifier le comportement du modèle (par exemple, en faisant en sorte que le modèle classifie les échantillons de manière incorrecte). Pour réduire la surface d’attaque exploitable des modèles, les scientifiques des données « renforcent » les modèles lors de l’entraînement pour garantir des performances de pointe et une résilience contre les attaques.
Deux idées reçues sur le Machine Learning
Idée reçue n° 1. Le Machine Learning est plus performant que les méthodes analytiques ou statistiques traditionnelles.
Bien que le Machine Learning puisse être un outil extrêmement efficace, il peut ne pas être adapté à toutes les catégories de problèmes. D’autres méthodes analytiques ou statistiques peuvent produire des résultats très précis et efficaces, ou s’avérer moins gourmandes en ressources que le Machine Learning, et constituer l’approche la plus adaptée pour une catégorie de problèmes donnée.
Idée reçue n° 2. Le Machine Learning doit être utilisé pour automatiser le plus de tâches possible.
Le Machine Learning peut être gourmand en ressources. En effet, il exige souvent un accès à d’importants volumes de données, à des ressources informatiques et à des équipes dédiées à l’analyse scientifique des données pour créer, entraîner et assurer la maintenance des modèles. Pour optimiser le retour sur investissement de la maintenance des modèles, mieux vaut les appliquer à des problèmes cibles à forte valeur ajoutée, récurrents, qui exigent vitesse et précision et qui disposent de référentiels de données de haute qualité en nombre suffisant pour assurer une formation et des tests continus.
L’approche de CrowdStrike en matière de Machine Learning
CrowdStrike applique le Machine Learning à l’échelle de la plateforme CrowdStrike Falcon® pour offrir une protection contre les menaces avancées.
Cyberveille de pointe fournie par l’architecture de sécurité cloud de CrowdStrike :
Les modèles de CrowdStrike sont entraînés grâce aux riches données télémétriques de l’architecture de sécurité cloud de CrowdStrike, qui mettent en corrélation des billions de points de données générés par Asset Graph, Intel Graph et la plateforme Threat Graph® brevetée pour offrir une visibilité inégalée et affiner en permanence la recherche de menaces sur toute la surface d’attaque d’une entreprise.
L’enrichissement de ces connaissances offre un corpus en constante évolution de vérité terrain générée par des équipes d’experts CrowdStrike, notamment les équipes de Threat Hunting (Falcon OverWatch™), le centre de recherche sur les logiciels malveillants et les équipes de détection et d’intervention managées (Falcon Complete™) de CrowdStrike.
Renforcement de l’expertise humaine :
Les modèles de CrowdStrike optimisent la détection des menaces et l’intervention autonomes, tout en renforçant l’expertise humaine dans des domaines clés, comme le Threat Hunting et les opérations informatiques et de sécurité. Les modèles de Machine Learning de la plateforme Falcon offrent une solution d’analyse de nouvelle génération qui automatise la détection des menaces et l’intervention, améliore l’efficacité des analystes grâce aux alertes ultrafiables générées par le Machine Learning et formule des recommandations intelligentes en matière de gestion des vulnérabilités pour assurer une défense proactive (avec le modèle ExPRT.AI de Falcon Spotlight™).
Plusieurs niveaux de défense :
CrowdStrike applique le Machine Learning sur toute la plateforme Falcon pour assurer une défense robuste et multiniveau tout au long du cycle de vie des processus (avant, pendant et après l’exécution). Avant l’exécution, les modèles de Machine Learning installés sur des capteurs et hébergés dans le cloud fonctionnent de manière synchrone pour détecter et neutraliser automatiquement les menaces, dotant ainsi l’agent Falcon léger d’une première ligne de défense solide. Grâce à la synchronicité constante entre les modèles de Machine Learning hébergés dans le cloud et ceux installés sur des capteurs, les détections effectuées sur les capteurs peuvent être appliquées sur toute une surface d’attaque, tandis que les détections réalisées par les modèles cloud peuvent être appliquées immédiatement sur tous les endpoints protégés.
Pour appuyer cette approche, CrowdStrike applique également une analyse comportementale avancée à l’exécution. Pour ce faire, il utilise des modèles cloud pour analyser les événements des endpoints et classifier les indicateurs d’attaque. Les indicateurs d’attaque pilotés par l’IA détectent les menaces émergentes de façon proactive, quels que soient les logiciels malveillants ou les outils utilisés, et fonctionnent de manière asynchrone avec les modèles installés sur des capteurs pour déclencher l’analyse locale des comportements suspects sur la base de la recherche de menaces en temps réel.
Après l’exécution, les indicateurs de comportement permettent d’évaluer les activités anormales sur toute la surface d’attaque d’une entreprise (comme en atteste l’indicateur CrowdStrike CrowdScore™, qui fournit un aperçu en temps réel du niveau de menace d’une entreprise). Ils sont également utilisés par Falcon OverWatch pour enquêter sur les menaces avancées, comme les activités « hands-on-keyboard », la cybercriminalité et les attaques furtives.